This week we will cover convolutional neural networks (CNNs)
Image analysis, video analysis, object detection
Note that we will not be going through any mathematics this week as the mathematics of CNNs is quite complicated but there are many good resources (including your textbook) if you are interested
Convolution refers to the mathematical combination of two functions to produce a third function
It merges two sets of information
The convolution is performed on the input data with the use of a filter or kernel (these terms are used interchangeably) to then produce a feature map.
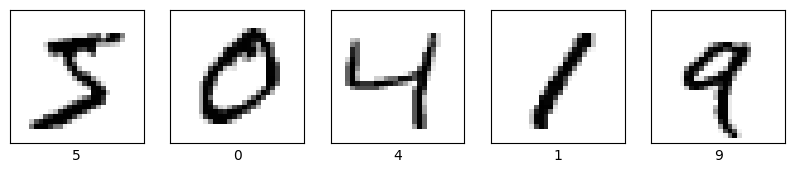
Photos (28 pixels by 28 pixels) of handwritten numeric digits as the input
Number shown in the photo as an output
Challenges: 2D data structure (images), variations in handwriting, low quality images, size of data set (60,000 images in the training set, 10,000 in the test set)
Import With Tensorflow
Also avaliable through Scikit-Learn, but does not come automatically split into a training and test set
import tensorflow as tf# Load MNIST datamnist = tf.keras.datasets.mnist(train_images, train_labels), (test_images, test_labels) = mnist.load_data()# Normalize the datatrain_images, test_images = train_images /255.0, test_images /255.0# Print the shape of the dataprint("Train images shape:", train_images.shape)print("Train labels shape:", train_labels.shape)print("Test images shape:", test_images.shape)print("Test labels shape:", test_labels.shape)
Train images shape: (60000, 28, 28)
Train labels shape: (60000,)
Test images shape: (10000, 28, 28)
Test labels shape: (10000,)
Let’s display some of the images
import matplotlib.pyplot as plt# Display a small number of imagesnum_images =5plt.figure(figsize=(10, 3))for i inrange(num_images): plt.subplot(1, num_images, i +1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(train_images[i], cmap=plt.cm.binary) plt.xlabel(train_labels[i])plt.show()
60k is a lot of images to have in a training set (though may be needed for large neural networks)
Let’s randomly select 5k images to use for training instead of 60k so networks train faster
Can use a smaller data set in the construction of your neural network (hyperparameter tuning process) but then use a larger sample to train the final network
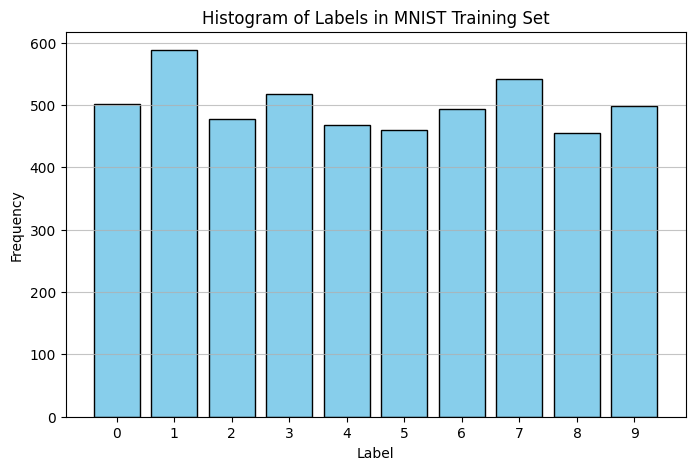
Classification can suffer from class imbalances. Let’s make sure our data is relatively evenly distributed.
# Create a histogram of the labelsplt.figure(figsize=(8, 5))plt.hist(train_labels_smaller, bins=range(11), align='left', rwidth=0.8, color='skyblue', edgecolor='black')plt.title('Histogram of Labels in MNIST Training Set')plt.xlabel('Label')plt.ylabel('Frequency')plt.xticks(range(10))plt.grid(axis='y', alpha=0.75)plt.show()
Classification with a Regular Neural Network
We can clasify the MNIST data with a regular neural network, but due to its architecture we have to flatten the data before it can reach the dense layers
Neural networks can be used to successfully classify images, but flattening the images can remove important patterns
Create a model that flattens the data (28x28 pixel images). We then have one hidden layer with 128 neurons and a Relu activation function, and an output layer with 10 neurons (10 possible outputs) and a softmax activation function since this is a classification.
from tensorflow.keras import layers, models# Build the modelmodel = models.Sequential([ layers.Flatten(input_shape=(28, 28)), layers.Dense(128, activation='relu'), layers.Dense(10, activation='softmax')])
For compiling the model we will use the Adam optimizer, our metric of success will be accuracy, and our loss function is sparse categorical cross-entropy
Sparse categorical cross-entropy is similiar to categorical cross-entropy but while categorical cross-entropy requires the data to be one-hot encoded prior to training the model, sparse categorical cross-entropy does not
# Compile the modelmodel.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
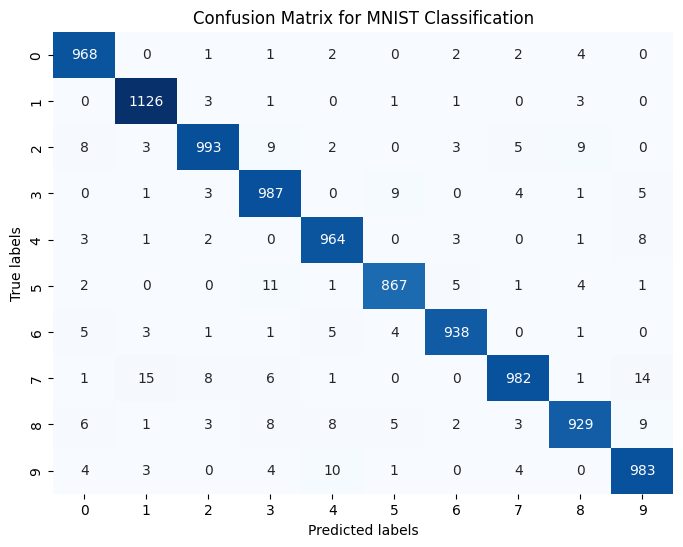
Train the model and the determine the accuracy
# Train the modelmodel.fit(train_images, train_labels, epochs=5, verbose=1)# Evaluate the modeltest_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)print('\nTest accuracy:', test_acc)
When we perform classification without one-hot encoding, the outputs of the model are not the class labels, but rather the probability that the input belongs to each class
# Predict the test sety_pred = model.predict(test_images)print(y_pred[0])
Tuple is the pool size (the size block over which to find the maximum)
Pooling layers reduce the dimensionality of the data while keeping the most important features
Two types of pooling layers: max pooling and average pooling
Stacking convolutional and pooling layers allows CNNS to learn in a heirarchical manner
First the networks learns basic featutes of the data (like edges and textures) and then more complicated features
This heirarchical learning is what makes CNNS so effective at image analysis
Note that not every convolutional layer has to be followed by a pooling layer, too many pooling layers can be bad
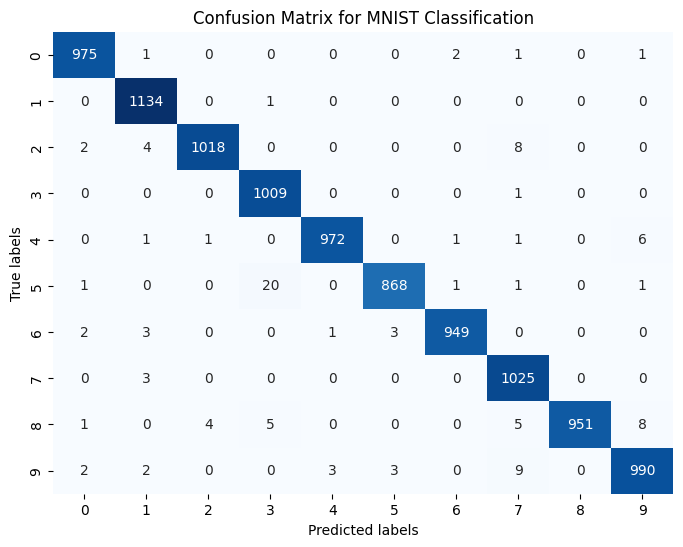
Full Neural Network for Classification
Have two pairs of convolutional layers/pooling layers of different sizes followed by a lone convolutional layer
The Flatten() layer is needed to take the 2D data down to one dimension for the dense layers
The first dense layer (a hidden layer) does some post-processing on the data that comes from the CNN layers, the second dense layer is the output layer
Because of the downsampling/dimensionality reduction performed by the convolutional and pooling layers, you can reduce the information passed onto the next layer to nothing (ValueError)
Tips to fix these errors:
Reduce the number of layers, especially the number of pooling layers
Reduce the pool size (minimum is (2,2))
Use the padding="same" for the Conv2D layers
These networks can take a very long time to train, especially with many filters, many layers, or a large amount of data