##############################
## IMPORTS ##
##############################
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso, Ridge
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE
from sklearn.datasets import fetch_california_housingModel Optimization and Nonlinear Models
CSC/DSC 340 Week 5 Slides
Author: Dr. Julie Butler
Date Created: August 19, 2023
Last Modified: September 18, 2023
Plan for the Week
Monday
Week 5 Pre-Class Homework and Week 4 In-Class Assignment Due
Lecture: Model Optimization and Nonlinear Models
Office Hours: 1pm - 3pm
Tuesday
Office Hours: 4pm - 6pm
Wednesday
Finish Lecture: Model Optimization and Nonlinear Models
Start Week 5 In-Class Assignment
Week 4 Post-Class Homework Due
Thursday
Office Hours: 12:30 - 2pm
Friday
In-Class Assignment Week 5
Problem Analysis Due Before Class (~1 page)
Part 1: Hyperparameter Tuning
Why do we need hyperparameter tuning?
- The values of the hyperparameters change the output of the model
- Bad hyperparameters lead to bad results
- New data set: California Housing
- Goal: Predict the price a house will sale for (house price/100k) given information about the house
- In-Class Week 5
# Print the features
fetch_california_housing().feature_names['MedInc',
'HouseAge',
'AveRooms',
'AveBedrms',
'Population',
'AveOccup',
'Latitude',
'Longitude']##############################
## IMPORT DATA ##
##############################
X, y = fetch_california_housing(return_X_y = True)##############################
## SCALE DATA ##
##############################
scaler = StandardScaler()
scaler.fit(X)
Z = scaler.transform(X)##############################
## TRAIN-TEST SPLIT ##
##############################
X_train, X_test, y_train, y_test = train_test_split(Z,y,test_size=0.2)##############################
## GOOD ALPHA ##
##############################
ridge = Ridge(alpha=1e-15)
ridge.fit(X_train, y_train)
y_pred = ridge.predict(X_test)
err = MSE(y_pred, y_test)
print("MSE:", err)
X_test_plot = scaler.inverse_transform(X_test)
plt.scatter(X_test_plot[:,1],y_test,label='True')
plt.scatter(X_test_plot[:,1],y_pred,label='Predicted')
plt.legend()MSE: 0.5130444814032065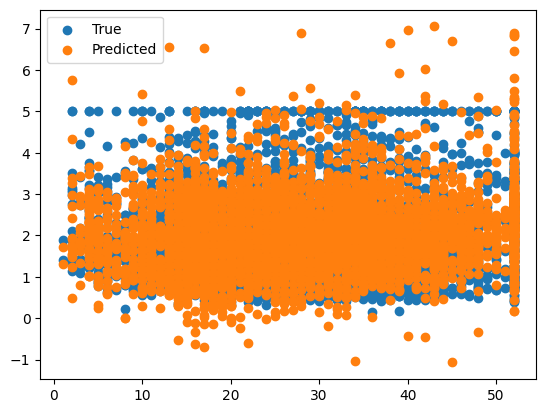
##############################
## BAD ALPHA ##
##############################
ridge = Ridge(alpha=1e15)
ridge.fit(X_train, y_train)
y_pred = ridge.predict(X_test)
err = MSE(y_pred, y_test)
print("MSE:", err)
X_test_plot = scaler.inverse_transform(X_test)
plt.scatter(X_test_plot[:,1],y_test,label='True')
plt.scatter(X_test_plot[:,1],y_pred,label='Predicted')MSE: 1.3242232149524624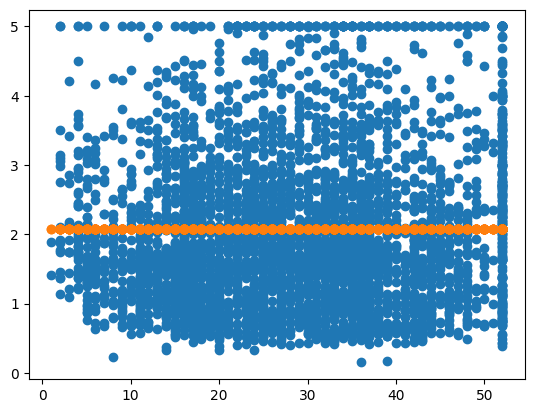
Methods for Hyperparameter Tuning
Using Default Values
- Scikit-Learn sets the default value of \(\alpha\) for ridge regression to 1.0, which is a reasonable high level of regularization
# Make the data set smaller (20k+ points in total)
# More points = more data to generate patterns BUT more run time
X = X[:1000]
y = y[:1000]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2)%%time
ridge = Ridge()
ridge.fit(X_train, y_train)
y_pred = ridge.predict(X_test)CPU times: user 10.1 ms, sys: 3.87 ms, total: 14 ms
Wall time: 2.23 mserr = MSE(y_pred, y_test)
print("MSE:", err)
X_test_plot = scaler.inverse_transform(X_test)
plt.scatter(X_test_plot[:,1],y_test,label='True')
plt.scatter(X_test_plot[:,1],y_pred,label='Predicted')MSE: 0.2524337853044928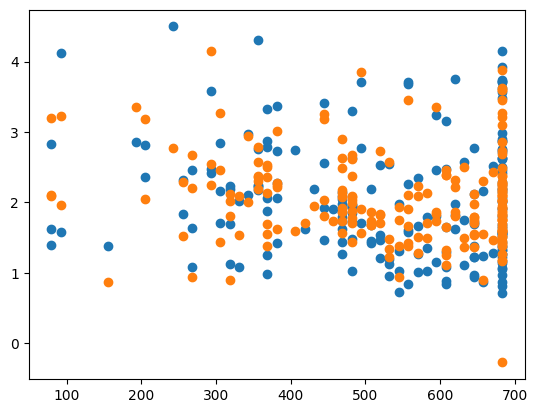
Pros
- Fast and no need to modify the algorithm
Cons
- Default value may not be the best value, but no test are done to check
For Loop Tuning
- Use a for loop to check many different values for the hyperparameters
- Can use nested for loops if more than one hyperparamter
%%time
best_err = 1e4
best_alpha = None
for alpha in np.logspace(-15,4,1000):
ridge = Ridge(alpha=alpha)
ridge.fit(X_train, y_train)
y_pred = ridge.predict(X_test)
err = MSE(y_pred, y_test)
if err < best_err:
best_err = err
best_alpha = alphaCPU times: user 739 ms, sys: 6.78 ms, total: 746 ms
Wall time: 363 msridge = Ridge(alpha=best_alpha)
ridge.fit(X_train, y_train)
y_pred = ridge.predict(X_test)
err = MSE(y_pred, y_test)
print("MSE:", err)
print("CHOSEN ALPHA:", best_alpha)
X_test_plot = scaler.inverse_transform(X_test)
plt.scatter(X_test_plot[:,1],y_test,label='True')
plt.scatter(X_test_plot[:,1],y_pred,label='Predicted')MSE: 0.24458222796367587
CHOSEN ALPHA: 1.0186101701559774e-14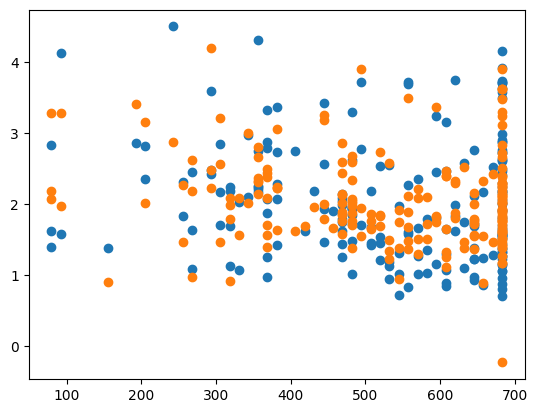
Pros
- Checks more than one value to find the best value
- Simple concept
- Short(ish) run times
Cons
- Long piece of code
- Not checking all possible values of the hyperparameters
GridSearchCV (Scikit-Learn)
- Scikit-Learn has several hyperparameter tuning implementation
- Grid search is a brute force algorithm which checks as many values as given
- If more than one hyperparameter, it checks every single possible combination
- “Same” test as for loops but gives much more information, but also takes longer
%%time
from sklearn.model_selection import GridSearchCV
parameters = {'alpha':np.logspace(-15,4,5000)}
ridge = Ridge()
grid_search = GridSearchCV(ridge, parameters,\
scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
print(grid_search.best_params_){'alpha': 1.28239437478694}
CPU times: user 12 s, sys: 113 ms, total: 12.1 s
Wall time: 11.7 sridge = Ridge(alpha=grid_search.best_params_['alpha'])
ridge.fit(X_train, y_train)
y_pred = ridge.predict(X_test)
err = MSE(y_pred, y_test)
print("MSE:", err)
print('CHOSEN ALPHA:', grid_search.best_params_['alpha'])
X_test_plot = scaler.inverse_transform(X_test)
plt.scatter(X_test_plot[:,1],y_test,label='True')
plt.scatter(X_test_plot[:,1],y_pred,label='Predicted')MSE: 0.25376962089748256
CHOSEN ALPHA: 1.28239437478694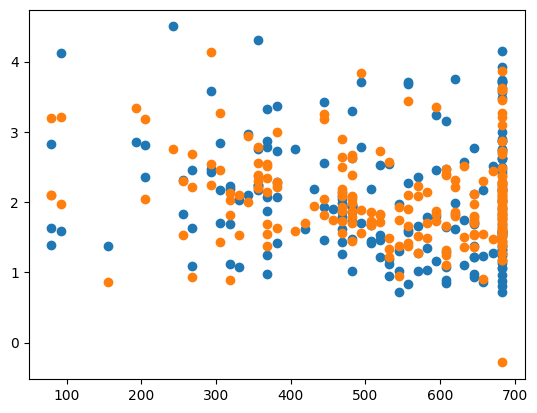
Pros
- Only takes a few lines to implement
- Gives a lot of data once it is fit
Cons
- Long run times
- Only searches the range of parameters given
RandomizedSearchCV (Scikit-Learn)
- Tries
n_iterrandomly chosen values for the hyperparmeters taken from a given distribution (uniform in this case)
%%time
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform
distributions = {'alpha':uniform(loc=0, scale=4)}
ridge = Ridge()
random_search = RandomizedSearchCV(ridge, distributions,\
scoring='neg_mean_squared_error', n_iter=5000)
random_search.fit(X_train, y_train)
print(random_search.best_params_, random_search.best_score_){'alpha': 1.28727476870728} -0.3095441456998481
CPU times: user 12.1 s, sys: 141 ms, total: 12.3 s
Wall time: 11.9 sridge = Ridge(alpha=random_search.best_params_['alpha'])
ridge.fit(X_train, y_train)
y_pred = ridge.predict(X_test)
err = MSE(y_pred, y_test)
print("MSE:", err)
print('CHOSEN ALPHA:', random_search.best_params_['alpha'])
X_test_plot = scaler.inverse_transform(X_test)
plt.scatter(X_test_plot[:,1],y_test,label='True')
plt.scatter(X_test_plot[:,1],y_pred,label='Predicted')MSE: 0.25379069257576914
CHOSEN ALPHA: 1.28727476870728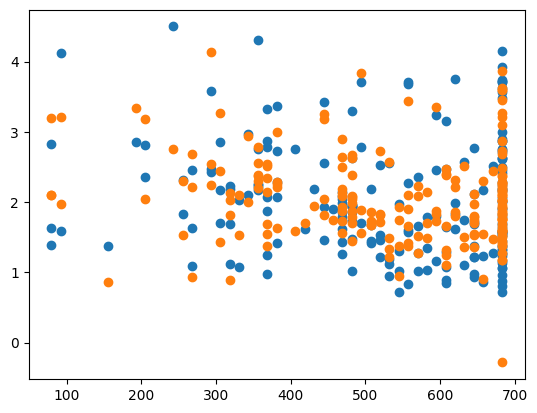
Pros
- Only takes a few lines to implement
- Gives a lot of data once it is fit
Cons
- Long run times (depending on value of
n_iter) - Only searches a finite number of parameter combinations
Bayesian Ridge Regression
- Finds the “most likely” value for \(\alpha\) using Bayesian stastics
- Leaves no uncertainity that the best value was just not sampled
%%time
from sklearn.linear_model import BayesianRidge
bayesian_ridge = BayesianRidge()
bayesian_ridge.fit(X_train, y_train)
y_pred = bayesian_ridge.predict(X_test)
print(bayesian_ridge.alpha_)3.3291096657245536
CPU times: user 8.29 ms, sys: 1.88 ms, total: 10.2 ms
Wall time: 2.94 msridge = BayesianRidge()
ridge.fit(X_train, y_train)
y_pred = ridge.predict(X_test)
err = MSE(y_pred, y_test)
print("MSE:", err)
print('CHOSEN ALPHA:', ridge.alpha_)
X_test_plot = scaler.inverse_transform(X_test)
plt.scatter(X_test_plot[:,1],y_test,label='True')
plt.scatter(X_test_plot[:,1],y_pred,label='Predicted')MSE: 0.2557831089861347
CHOSEN ALPHA: 3.3291096657245536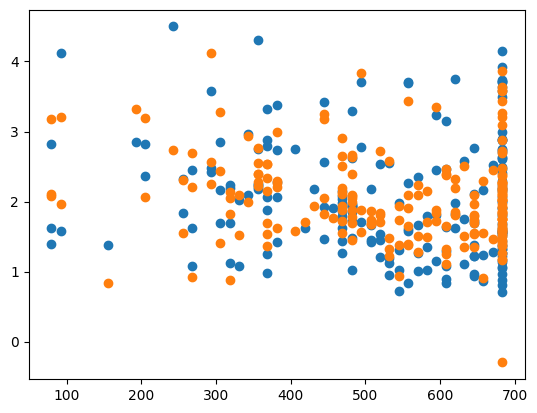
Pros
- Only takes a few lines to implement
- Statical certainity that the given \(\alpha\) value is the best value
- Short run times
Cons
- Only valid for Bayesian ridge regression (linear model)
Comparison of \(\alpha\), Accuracy, and Run Time
- Exact values depend on the train-test split and RandomizedSearch results; these values were taken from one run
labels = ['default', 'for loops', 'GridSearchCV', 'RandomizedSearchCV', 'Bayesian']
alphas = [1.0, 1e-15, 769.79, 3.99, 1.90]
mse = [0.23461613368850237, 0.2343672966024232, 0.23546465060931623, 0.23546192678932165, 0.23439940455100014]
run_times = [20.8/1000, 1.35, 57.7, 7*60+40, 1.18] #msplt.bar(np.arange(0,len(labels)), alphas)
plt.yscale('log')
plt.xticks(np.arange(0,len(labels)), labels, rotation=45)
plt.ylabel(r"Best $\alpha$ Value")
plt.xlabel("Hyperparameter Tuning Method")Text(0.5, 0, 'Hyperparameter Tuning Method')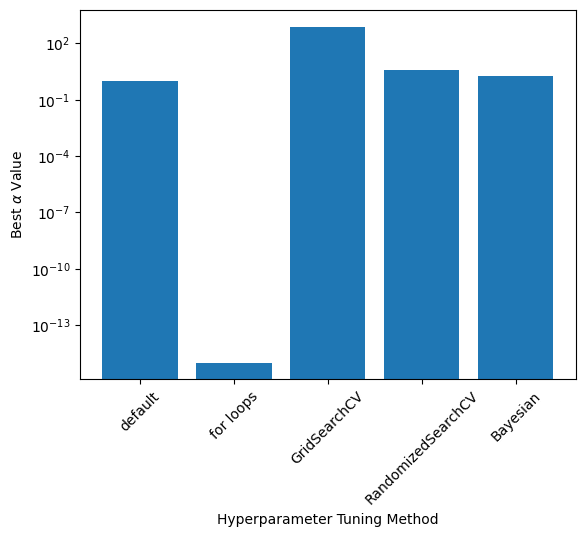
plt.bar(np.arange(0,len(labels)), mse)
plt.xticks(np.arange(0,len(labels)), labels, rotation=45)
plt.ylabel(r"MSE")
plt.xlabel("Hyperparameter Tuning Method")Text(0.5, 0, 'Hyperparameter Tuning Method')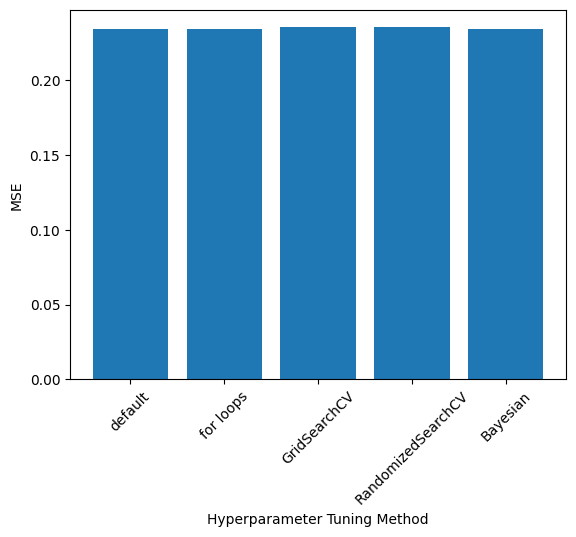
plt.bar(np.arange(0,len(labels)), run_times)
plt.xticks(np.arange(0,len(labels)), labels, rotation=45)
plt.ylabel(r"Run Time (sec.)")
plt.xlabel("Hyperparameter Tuning Method")
plt.yscale('log')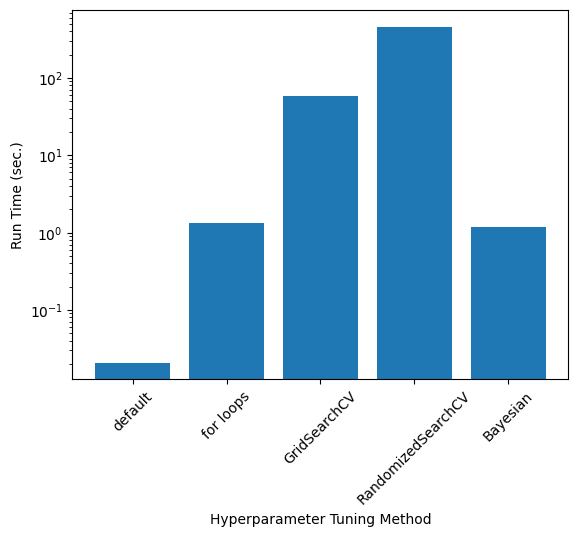
Part 2: Feature Engineering
Feature engineering is the process of eliminating or altering given inputs in order to improve the model’s predictions * Design matrix/alter the inputs * Remove features that are not useful * Scaling the features or targets
import pandas as pd
import seaborn as sns
housing = fetch_california_housing()
housing_data = pd.DataFrame(housing.data, columns=housing.feature_names)
housing_data['target'] = housing.target
housing_data = housing_data.sample(1000)Pairplots can give us initial ideas about the data set and and obvious relations
sns.pairplot(housing_data)/Users/butlerju/Library/Python/3.9/lib/python/site-packages/seaborn/axisgrid.py:118: UserWarning: The figure layout has changed to tight
self._figure.tight_layout(*args, **kwargs)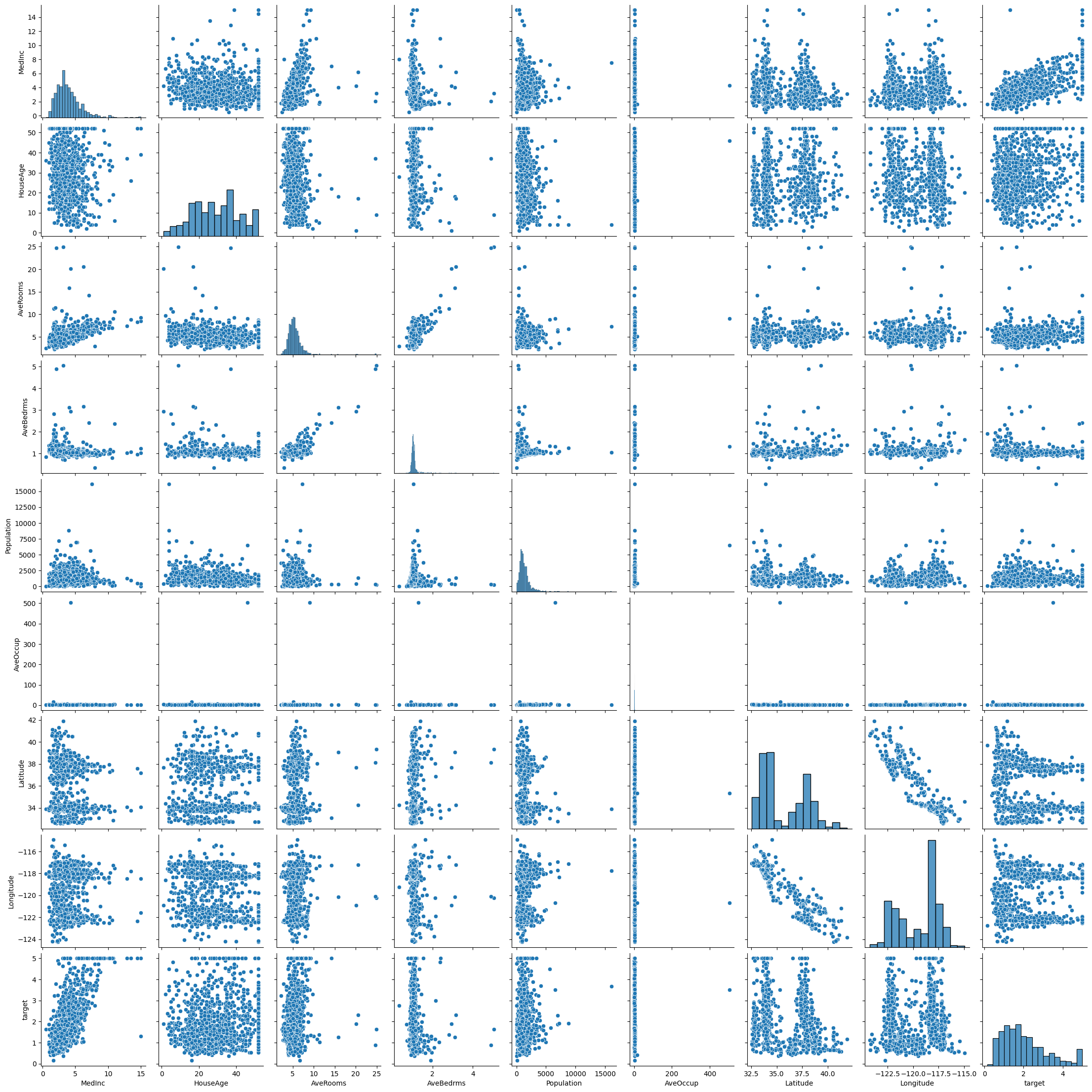
# Remove outliers from the data set and make the pairplot again
from scipy import stats
housing_data = housing_data[(np.abs(stats.zscore(housing_data)) < 3).all(axis=1)]
sns.pairplot(housing_data)/Users/butlerju/Library/Python/3.9/lib/python/site-packages/seaborn/axisgrid.py:118: UserWarning: The figure layout has changed to tight
self._figure.tight_layout(*args, **kwargs)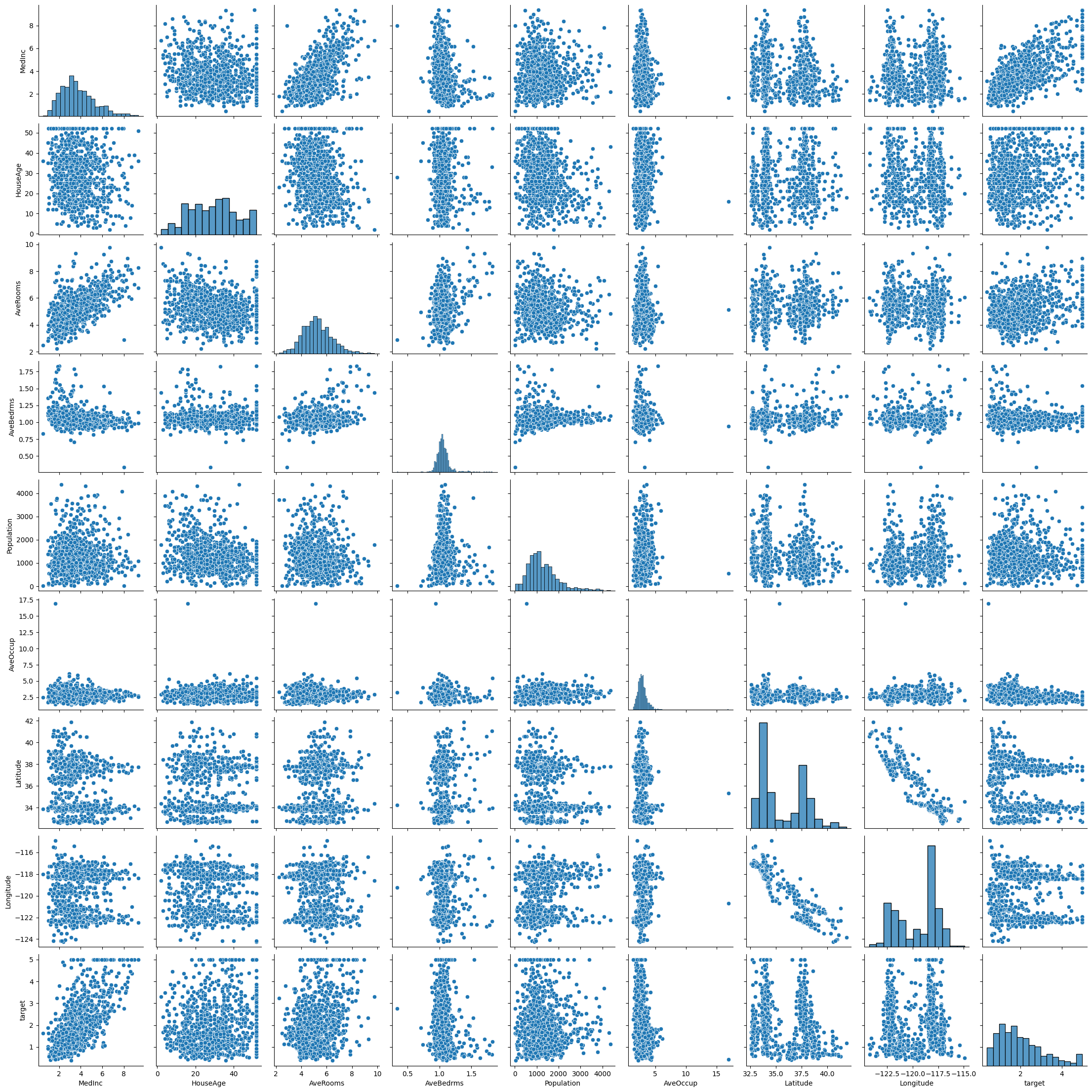
Correlation Matrix
- Correlation score = \(\sqrt{R2\ Score}\)
- Values close to \(\pm1\) means that the two feautures are linearly related
correlation_matrix = housing_data.corr()
correlation_matrix| MedInc | HouseAge | AveRooms | AveBedrms | Population | AveOccup | Latitude | Longitude | target | |
|---|---|---|---|---|---|---|---|---|---|
| MedInc | 1.000000 | -0.127566 | 0.610847 | -0.256800 | 0.007924 | -0.082699 | -0.116213 | 0.016332 | 0.660433 |
| HouseAge | -0.127566 | 1.000000 | -0.210621 | -0.055660 | -0.277599 | -0.050325 | 0.038883 | -0.141344 | 0.152904 |
| AveRooms | 0.610847 | -0.210621 | 1.000000 | 0.242756 | -0.092520 | 0.000591 | 0.126202 | -0.069170 | 0.236683 |
| AveBedrms | -0.256800 | -0.055660 | 0.242756 | 1.000000 | 0.002127 | -0.077425 | 0.095422 | -0.006674 | -0.116612 |
| Population | 0.007924 | -0.277599 | -0.092520 | 0.002127 | 1.000000 | 0.139321 | -0.152725 | 0.127278 | 0.001396 |
| AveOccup | -0.082699 | -0.050325 | 0.000591 | -0.077425 | 0.139321 | 1.000000 | -0.144107 | 0.150209 | -0.280276 |
| Latitude | -0.116213 | 0.038883 | 0.126202 | 0.095422 | -0.152725 | -0.144107 | 1.000000 | -0.930766 | -0.181499 |
| Longitude | 0.016332 | -0.141344 | -0.069170 | -0.006674 | 0.127278 | 0.150209 | -0.930766 | 1.000000 | -0.013877 |
| target | 0.660433 | 0.152904 | 0.236683 | -0.116612 | 0.001396 | -0.280276 | -0.181499 | -0.013877 | 1.000000 |
plt.matshow(correlation_matrix)
plt.colorbar()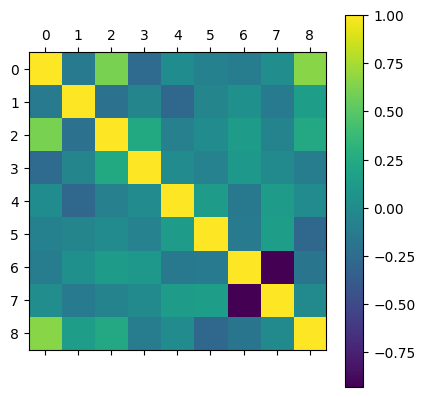
LASSO Regression for Feature Selection
lasso = Lasso()
lasso.fit(X,y)
ypred = lasso.predict(X)
print(MSE(ypred,y))
lasso.coef_0.9517091796179739array([ 1.45469232e-01, 5.81496884e-03, 0.00000000e+00, -0.00000000e+00,
-6.37292607e-06, -0.00000000e+00, -0.00000000e+00, -0.00000000e+00])Accuracy with All Data (Scaled)
X = housing_data.drop(columns=['target'])
y = housing_data['target']
scaler = StandardScaler()
scaler.fit(X)
Z = scaler.transform(X)
X_train, X_test, y_train, y_test = train_test_split(Z,y,test_size=0.2)
bayesian_ridge = BayesianRidge()
bayesian_ridge.fit(X_train, y_train)
y_pred = bayesian_ridge.predict(X_test)
print('MSE:', MSE(y_pred, y_test))MSE: 0.4450864919944219Part 3: Nonlinear Models
Kernel Ridge Regression (KRR)
- All previous models we have studied have been linear–capable of modeling linear patterns
- Design matrices can only add some much functions
- Many data sets will have a nonlinear pattern and thus we need a nonlinear model
- Kernel ridge regression (KRR)
- Support vector machines (SVMs)
- Neural Networks
Kernel Functions
Scikit-Learn kernels are found here
- Linear: \(k(x,y) = x^Ty\)
- Polynomial: k(x,y) = \((\gamma x^Ty+c_0)^d\)
- Sigmoid: \(k(x,y) = tanh(\gamma x^Ty+c_0)\)
- Radial Basis Function (RBF): \(k(x,y) = exp(-\gamma||x-y||_2)\)
Inputs to KRR algorithm are modified by the kernel function, thus giving the method nonlinearuty \(\longrightarrow\) kernel methods/trick allows linear methods to solve nonlinear problems
- Kernel ridge regression is just ridge regression with the inputs modified by the kernel function
KRR Equations
- Form of predictions: \(\hat{y}(x) = \sum_{i=1}^m \theta_ik(x_i,x)\)
- Loss function:\(J(\theta) = MSE(y,\hat{y}) + \frac{\alpha}{2}\sum_{i=1}^n\theta_i^2\)
- Optimized parameters: \(\theta = (\textbf{K}-\alpha\textbf{I})^{-1}y\)
- \(\textbf{K} = k(x_i, x_j)\)
Hyperparameter Tuning with Many Hyperparameters
- KRR has the same hyperparameter as ridge regression: \(\alpha\)
- Each kernel function has 0-3 hyperparameters
- The choice of kernel function is a hyperparameter
- Hyperparameter tuning becomes more important as the number of hyperparameters in the model increases
Housing Data with Kernel Ridge Regression
from sklearn.kernel_ridge import KernelRidge
X,y = fetch_california_housing(return_X_y=True)
X = X[:500]
y = y[:500]
scaler = StandardScaler()
scaler.fit(X)
Z = scaler.transform(X)
X_train, X_test, y_train, y_test = train_test_split(Z,y,test_size=0.2)
krr = KernelRidge()
krr.fit(X_train, y_train)
y_pred = krr.predict(X_test)
print("MSE:", MSE(y_pred, y_test))MSE: 4.251786779991435
distributions = {'alpha':uniform(loc=0, scale=4), 'kernel':['linear', \
'polynomial', 'rbf', \
'sigmoid', 'laplacian'], \
'gamma':uniform(loc=0, scale=4),\
'degree':np.arange(0,10), 'coef0':uniform(loc=0, scale=4)}
krr = KernelRidge()
random_search = RandomizedSearchCV(krr, distributions,\
scoring='neg_mean_squared_error', n_iter=50)
random_search.fit(X_train, y_train)
print(random_search)
print(random_search.best_params_, random_search.best_score_)/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:248: LinAlgWarning: Ill-conditioned matrix (rcond=5.3244e-18): result may not be accurate.
dual_coef = linalg.solve(K, y, assume_a="pos", overwrite_a=False)
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:248: LinAlgWarning: Ill-conditioned matrix (rcond=8.32643e-18): result may not be accurate.
dual_coef = linalg.solve(K, y, assume_a="pos", overwrite_a=False)
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:248: LinAlgWarning: Ill-conditioned matrix (rcond=4.88364e-18): result may not be accurate.
dual_coef = linalg.solve(K, y, assume_a="pos", overwrite_a=False)
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:248: LinAlgWarning: Ill-conditioned matrix (rcond=6.18405e-18): result may not be accurate.
dual_coef = linalg.solve(K, y, assume_a="pos", overwrite_a=False)
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py:824: UserWarning: Scoring failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py", line 813, in _score
scores = scorer(estimator, X_test, y_test)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 266, in __call__
return self._score(partial(_cached_call, None), estimator, X, y_true, **_kwargs)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 353, in _score
y_pred = method_caller(estimator, "predict", X)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 86, in _cached_call
result, _ = _get_response_values(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_response.py", line 109, in _get_response_values
y_pred, pos_label = estimator.predict(X), None
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 236, in predict
K = self._get_kernel(X, self.X_fit_)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 168, in _get_kernel
return pairwise_kernels(X, Y, metric=self.kernel, filter_params=True, **params)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 2365, in pairwise_kernels
return _parallel_pairwise(X, Y, func, n_jobs, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 1765, in _parallel_pairwise
return func(X, Y, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 201, in wrapper
validate_parameter_constraints(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 95, in validate_parameter_constraints
raise InvalidParameterError(
sklearn.utils._param_validation.InvalidParameterError: The 'degree' parameter of polynomial_kernel must be a float in the range [1.0, inf). Got 0 instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py:824: UserWarning: Scoring failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py", line 813, in _score
scores = scorer(estimator, X_test, y_test)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 266, in __call__
return self._score(partial(_cached_call, None), estimator, X, y_true, **_kwargs)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 353, in _score
y_pred = method_caller(estimator, "predict", X)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 86, in _cached_call
result, _ = _get_response_values(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_response.py", line 109, in _get_response_values
y_pred, pos_label = estimator.predict(X), None
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 236, in predict
K = self._get_kernel(X, self.X_fit_)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 168, in _get_kernel
return pairwise_kernels(X, Y, metric=self.kernel, filter_params=True, **params)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 2365, in pairwise_kernels
return _parallel_pairwise(X, Y, func, n_jobs, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 1765, in _parallel_pairwise
return func(X, Y, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 201, in wrapper
validate_parameter_constraints(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 95, in validate_parameter_constraints
raise InvalidParameterError(
sklearn.utils._param_validation.InvalidParameterError: The 'degree' parameter of polynomial_kernel must be a float in the range [1.0, inf). Got 0 instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py:824: UserWarning: Scoring failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py", line 813, in _score
scores = scorer(estimator, X_test, y_test)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 266, in __call__
return self._score(partial(_cached_call, None), estimator, X, y_true, **_kwargs)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 353, in _score
y_pred = method_caller(estimator, "predict", X)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 86, in _cached_call
result, _ = _get_response_values(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_response.py", line 109, in _get_response_values
y_pred, pos_label = estimator.predict(X), None
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 236, in predict
K = self._get_kernel(X, self.X_fit_)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 168, in _get_kernel
return pairwise_kernels(X, Y, metric=self.kernel, filter_params=True, **params)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 2365, in pairwise_kernels
return _parallel_pairwise(X, Y, func, n_jobs, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 1765, in _parallel_pairwise
return func(X, Y, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 201, in wrapper
validate_parameter_constraints(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 95, in validate_parameter_constraints
raise InvalidParameterError(
sklearn.utils._param_validation.InvalidParameterError: The 'degree' parameter of polynomial_kernel must be a float in the range [1.0, inf). Got 0 instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py:824: UserWarning: Scoring failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py", line 813, in _score
scores = scorer(estimator, X_test, y_test)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 266, in __call__
return self._score(partial(_cached_call, None), estimator, X, y_true, **_kwargs)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 353, in _score
y_pred = method_caller(estimator, "predict", X)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 86, in _cached_call
result, _ = _get_response_values(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_response.py", line 109, in _get_response_values
y_pred, pos_label = estimator.predict(X), None
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 236, in predict
K = self._get_kernel(X, self.X_fit_)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 168, in _get_kernel
return pairwise_kernels(X, Y, metric=self.kernel, filter_params=True, **params)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 2365, in pairwise_kernels
return _parallel_pairwise(X, Y, func, n_jobs, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 1765, in _parallel_pairwise
return func(X, Y, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 201, in wrapper
validate_parameter_constraints(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 95, in validate_parameter_constraints
raise InvalidParameterError(
sklearn.utils._param_validation.InvalidParameterError: The 'degree' parameter of polynomial_kernel must be a float in the range [1.0, inf). Got 0 instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py:824: UserWarning: Scoring failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py", line 813, in _score
scores = scorer(estimator, X_test, y_test)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 266, in __call__
return self._score(partial(_cached_call, None), estimator, X, y_true, **_kwargs)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 353, in _score
y_pred = method_caller(estimator, "predict", X)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 86, in _cached_call
result, _ = _get_response_values(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_response.py", line 109, in _get_response_values
y_pred, pos_label = estimator.predict(X), None
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 236, in predict
K = self._get_kernel(X, self.X_fit_)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 168, in _get_kernel
return pairwise_kernels(X, Y, metric=self.kernel, filter_params=True, **params)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 2365, in pairwise_kernels
return _parallel_pairwise(X, Y, func, n_jobs, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 1765, in _parallel_pairwise
return func(X, Y, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 201, in wrapper
validate_parameter_constraints(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 95, in validate_parameter_constraints
raise InvalidParameterError(
sklearn.utils._param_validation.InvalidParameterError: The 'degree' parameter of polynomial_kernel must be a float in the range [1.0, inf). Got 0 instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:248: LinAlgWarning: Ill-conditioned matrix (rcond=1.10973e-16): result may not be accurate.
dual_coef = linalg.solve(K, y, assume_a="pos", overwrite_a=False)
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:248: LinAlgWarning: Ill-conditioned matrix (rcond=9.38963e-17): result may not be accurate.
dual_coef = linalg.solve(K, y, assume_a="pos", overwrite_a=False)
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py:824: UserWarning: Scoring failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py", line 813, in _score
scores = scorer(estimator, X_test, y_test)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 266, in __call__
return self._score(partial(_cached_call, None), estimator, X, y_true, **_kwargs)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 353, in _score
y_pred = method_caller(estimator, "predict", X)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 86, in _cached_call
result, _ = _get_response_values(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_response.py", line 109, in _get_response_values
y_pred, pos_label = estimator.predict(X), None
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 236, in predict
K = self._get_kernel(X, self.X_fit_)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 168, in _get_kernel
return pairwise_kernels(X, Y, metric=self.kernel, filter_params=True, **params)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 2365, in pairwise_kernels
return _parallel_pairwise(X, Y, func, n_jobs, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 1765, in _parallel_pairwise
return func(X, Y, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 201, in wrapper
validate_parameter_constraints(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 95, in validate_parameter_constraints
raise InvalidParameterError(
sklearn.utils._param_validation.InvalidParameterError: The 'degree' parameter of polynomial_kernel must be a float in the range [1.0, inf). Got 0 instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py:824: UserWarning: Scoring failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py", line 813, in _score
scores = scorer(estimator, X_test, y_test)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 266, in __call__
return self._score(partial(_cached_call, None), estimator, X, y_true, **_kwargs)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 353, in _score
y_pred = method_caller(estimator, "predict", X)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 86, in _cached_call
result, _ = _get_response_values(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_response.py", line 109, in _get_response_values
y_pred, pos_label = estimator.predict(X), None
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 236, in predict
K = self._get_kernel(X, self.X_fit_)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 168, in _get_kernel
return pairwise_kernels(X, Y, metric=self.kernel, filter_params=True, **params)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 2365, in pairwise_kernels
return _parallel_pairwise(X, Y, func, n_jobs, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 1765, in _parallel_pairwise
return func(X, Y, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 201, in wrapper
validate_parameter_constraints(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 95, in validate_parameter_constraints
raise InvalidParameterError(
sklearn.utils._param_validation.InvalidParameterError: The 'degree' parameter of polynomial_kernel must be a float in the range [1.0, inf). Got 0 instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py:824: UserWarning: Scoring failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py", line 813, in _score
scores = scorer(estimator, X_test, y_test)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 266, in __call__
return self._score(partial(_cached_call, None), estimator, X, y_true, **_kwargs)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 353, in _score
y_pred = method_caller(estimator, "predict", X)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 86, in _cached_call
result, _ = _get_response_values(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_response.py", line 109, in _get_response_values
y_pred, pos_label = estimator.predict(X), None
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 236, in predict
K = self._get_kernel(X, self.X_fit_)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 168, in _get_kernel
return pairwise_kernels(X, Y, metric=self.kernel, filter_params=True, **params)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 2365, in pairwise_kernels
return _parallel_pairwise(X, Y, func, n_jobs, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 1765, in _parallel_pairwise
return func(X, Y, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 201, in wrapper
validate_parameter_constraints(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 95, in validate_parameter_constraints
raise InvalidParameterError(
sklearn.utils._param_validation.InvalidParameterError: The 'degree' parameter of polynomial_kernel must be a float in the range [1.0, inf). Got 0 instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py:824: UserWarning: Scoring failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py", line 813, in _score
scores = scorer(estimator, X_test, y_test)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 266, in __call__
return self._score(partial(_cached_call, None), estimator, X, y_true, **_kwargs)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 353, in _score
y_pred = method_caller(estimator, "predict", X)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 86, in _cached_call
result, _ = _get_response_values(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_response.py", line 109, in _get_response_values
y_pred, pos_label = estimator.predict(X), None
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 236, in predict
K = self._get_kernel(X, self.X_fit_)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 168, in _get_kernel
return pairwise_kernels(X, Y, metric=self.kernel, filter_params=True, **params)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 2365, in pairwise_kernels
return _parallel_pairwise(X, Y, func, n_jobs, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 1765, in _parallel_pairwise
return func(X, Y, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 201, in wrapper
validate_parameter_constraints(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 95, in validate_parameter_constraints
raise InvalidParameterError(
sklearn.utils._param_validation.InvalidParameterError: The 'degree' parameter of polynomial_kernel must be a float in the range [1.0, inf). Got 0 instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py:824: UserWarning: Scoring failed. The score on this train-test partition for these parameters will be set to nan. Details:
Traceback (most recent call last):
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_validation.py", line 813, in _score
scores = scorer(estimator, X_test, y_test)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 266, in __call__
return self._score(partial(_cached_call, None), estimator, X, y_true, **_kwargs)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 353, in _score
y_pred = method_caller(estimator, "predict", X)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/_scorer.py", line 86, in _cached_call
result, _ = _get_response_values(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_response.py", line 109, in _get_response_values
y_pred, pos_label = estimator.predict(X), None
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 236, in predict
K = self._get_kernel(X, self.X_fit_)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/kernel_ridge.py", line 168, in _get_kernel
return pairwise_kernels(X, Y, metric=self.kernel, filter_params=True, **params)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 2365, in pairwise_kernels
return _parallel_pairwise(X, Y, func, n_jobs, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/metrics/pairwise.py", line 1765, in _parallel_pairwise
return func(X, Y, **kwds)
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 201, in wrapper
validate_parameter_constraints(
File "/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/utils/_param_validation.py", line 95, in validate_parameter_constraints
raise InvalidParameterError(
sklearn.utils._param_validation.InvalidParameterError: The 'degree' parameter of polynomial_kernel must be a float in the range [1.0, inf). Got 0 instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:248: LinAlgWarning: Ill-conditioned matrix (rcond=1.01841e-16): result may not be accurate.
dual_coef = linalg.solve(K, y, assume_a="pos", overwrite_a=False)
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/linear_model/_ridge.py:250: UserWarning: Singular matrix in solving dual problem. Using least-squares solution instead.
warnings.warn(
/Users/butlerju/Library/Python/3.9/lib/python/site-packages/sklearn/model_selection/_search.py:976: UserWarning: One or more of the test scores are non-finite: [-2.42006291e+08 -1.77339774e+02 -4.83129184e+03 -4.08145877e+00
-3.97789133e+00 -4.58826578e+00 -3.47220108e+00 nan
-1.79712917e+00 -4.07407928e+00 -8.88568928e+04 -3.58458910e+00
-1.16867320e+07 -4.08268562e+00 -1.62536283e+07 -4.08205880e+00
-4.58634418e+00 -5.70712854e-01 -1.81246863e+02 -4.60330380e+00
-1.53538542e+07 -4.63645646e-01 nan -2.50026003e+00
-4.07442006e+00 -6.59960361e+05 -4.18486544e+02 -4.17276357e+00
-4.60910142e+00 -4.59418797e+00 -2.96482063e-01 -4.96422597e+00
-4.07354581e+00 -4.07402266e+00 -3.34747234e+00 -3.94346236e-01
-8.81917621e+01 -4.59778279e+08 -4.26253801e+00 -4.07825517e+00
-2.96611302e-01 -4.59302279e+00 -4.46274691e+00 -3.40350899e+04
-1.48204916e+02 -3.28833776e+00 -1.49977617e+00 -4.97350843e-01
-2.96821018e-01 -3.17877908e+00]
warnings.warn(RandomizedSearchCV(estimator=KernelRidge(), n_iter=50,
param_distributions={'alpha': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x28d8c58e0>,
'coef0': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x28d8d4790>,
'degree': array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]),
'gamma': <scipy.stats._distn_infrastructure.rv_continuous_frozen object at 0x28d8c5730>,
'kernel': ['linear', 'polynomial',
'rbf', 'sigmoid',
'laplacian']},
scoring='neg_mean_squared_error')
{'alpha': 3.1155765043068264, 'coef0': 3.162204720865116, 'degree': 1, 'gamma': 2.0997142074701114, 'kernel': 'polynomial'} -0.296482062515431X,y = fetch_california_housing(return_X_y=True)
scaler = StandardScaler()
scaler.fit(X)
Z = scaler.transform(X)
X_train, X_test, y_train, y_test = train_test_split(Z,y,test_size=0.2)# Using the best parameters from through one run of the
# RandomizedSearchCV method above
krr = KernelRidge(alpha= 0.35753693232459094, coef0= 3.2725118241858264, degree= 9, gamma= 0.14696609545731532, kernel= 'laplacian')
krr.fit(X_train, y_train)
y_pred = krr.predict(X_test)
print('MSE:', MSE(y_pred, y_test))MSE: 0.23499324697787755bayesian_ridge = BayesianRidge()
bayesian_ridge.fit(X_train, y_train)
y_pred = bayesian_ridge.predict(X_test)
print('MSE:', MSE(y_pred, y_test))MSE: 0.5242651488478602