Unsupervised Machine Learning: Clustering and Dimensionality Reduction#
CSC/DSC 340 Week 6 Slides
Author: Dr. Julie Butler
Date Created: August 24, 2023
Last Modified: August 29, 2023
##############################
## IMPORTS ##
##############################
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.cm as cm
from sklearn.svm import SVC
import matplotlib.pyplot as plt
from scipy.stats import uniform
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.pipeline import Pipeline
from sklearn.datasets import load_wine
from sklearn.metrics import confusion_matrix
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as mse
from sklearn.model_selection import RandomizedSearchCV
from sklearn.metrics import silhouette_samples, silhouette_score
from sklearn.metrics import accuracy_score, classification_report
Wine Data Set (Classification)#
178 data points with 13 features and 3 different target values
Goal: given information about a wine, predict which of three locations it originated from
Data set challenges: varying scales and class imbalance
wine = load_wine()
wine_data = pd.DataFrame(data=wine.data, columns=wine.feature_names)
wine_data['labels'] = wine.target
wine_data
| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline | labels | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 | 0 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050.0 | 0 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185.0 | 0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480.0 | 0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735.0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 173 | 13.71 | 5.65 | 2.45 | 20.5 | 95.0 | 1.68 | 0.61 | 0.52 | 1.06 | 7.70 | 0.64 | 1.74 | 740.0 | 2 |
| 174 | 13.40 | 3.91 | 2.48 | 23.0 | 102.0 | 1.80 | 0.75 | 0.43 | 1.41 | 7.30 | 0.70 | 1.56 | 750.0 | 2 |
| 175 | 13.27 | 4.28 | 2.26 | 20.0 | 120.0 | 1.59 | 0.69 | 0.43 | 1.35 | 10.20 | 0.59 | 1.56 | 835.0 | 2 |
| 176 | 13.17 | 2.59 | 2.37 | 20.0 | 120.0 | 1.65 | 0.68 | 0.53 | 1.46 | 9.30 | 0.60 | 1.62 | 840.0 | 2 |
| 177 | 14.13 | 4.10 | 2.74 | 24.5 | 96.0 | 2.05 | 0.76 | 0.56 | 1.35 | 9.20 | 0.61 | 1.60 | 560.0 | 2 |
178 rows × 14 columns
sns.pairplot(wine_data, hue='labels')
/Users/juliehartley/Library/Python/3.9/lib/python/site-packages/seaborn/axisgrid.py:118: UserWarning: The figure layout has changed to tight
self._figure.tight_layout(*args, **kwargs)
<seaborn.axisgrid.PairGrid at 0x1055f5580>
Error in callback <function flush_figures at 0x1540beb80> (for post_execute):
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib_inline/backend_inline.py:126, in flush_figures()
123 if InlineBackend.instance().close_figures:
124 # ignore the tracking, just draw and close all figures
125 try:
--> 126 return show(True)
127 except Exception as e:
128 # safely show traceback if in IPython, else raise
129 ip = get_ipython()
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib_inline/backend_inline.py:90, in show(close, block)
88 try:
89 for figure_manager in Gcf.get_all_fig_managers():
---> 90 display(
91 figure_manager.canvas.figure,
92 metadata=_fetch_figure_metadata(figure_manager.canvas.figure)
93 )
94 finally:
95 show._to_draw = []
File ~/Library/Python/3.9/lib/python/site-packages/IPython/core/display_functions.py:298, in display(include, exclude, metadata, transient, display_id, raw, clear, *objs, **kwargs)
296 publish_display_data(data=obj, metadata=metadata, **kwargs)
297 else:
--> 298 format_dict, md_dict = format(obj, include=include, exclude=exclude)
299 if not format_dict:
300 # nothing to display (e.g. _ipython_display_ took over)
301 continue
File ~/Library/Python/3.9/lib/python/site-packages/IPython/core/formatters.py:178, in DisplayFormatter.format(self, obj, include, exclude)
176 md = None
177 try:
--> 178 data = formatter(obj)
179 except:
180 # FIXME: log the exception
181 raise
File ~/Library/Python/3.9/lib/python/site-packages/decorator.py:232, in decorate.<locals>.fun(*args, **kw)
230 if not kwsyntax:
231 args, kw = fix(args, kw, sig)
--> 232 return caller(func, *(extras + args), **kw)
File ~/Library/Python/3.9/lib/python/site-packages/IPython/core/formatters.py:222, in catch_format_error(method, self, *args, **kwargs)
220 """show traceback on failed format call"""
221 try:
--> 222 r = method(self, *args, **kwargs)
223 except NotImplementedError:
224 # don't warn on NotImplementedErrors
225 return self._check_return(None, args[0])
File ~/Library/Python/3.9/lib/python/site-packages/IPython/core/formatters.py:339, in BaseFormatter.__call__(self, obj)
337 pass
338 else:
--> 339 return printer(obj)
340 # Finally look for special method names
341 method = get_real_method(obj, self.print_method)
File ~/Library/Python/3.9/lib/python/site-packages/IPython/core/pylabtools.py:151, in print_figure(fig, fmt, bbox_inches, base64, **kwargs)
148 from matplotlib.backend_bases import FigureCanvasBase
149 FigureCanvasBase(fig)
--> 151 fig.canvas.print_figure(bytes_io, **kw)
152 data = bytes_io.getvalue()
153 if fmt == 'svg':
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib/backend_bases.py:2346, in FigureCanvasBase.print_figure(self, filename, dpi, facecolor, edgecolor, orientation, format, bbox_inches, pad_inches, bbox_extra_artists, backend, **kwargs)
2344 if bbox_inches:
2345 if bbox_inches == "tight":
-> 2346 bbox_inches = self.figure.get_tightbbox(
2347 renderer, bbox_extra_artists=bbox_extra_artists)
2348 if pad_inches is None:
2349 pad_inches = rcParams['savefig.pad_inches']
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib/figure.py:1785, in FigureBase.get_tightbbox(self, renderer, bbox_extra_artists)
1781 if ax.get_visible():
1782 # some axes don't take the bbox_extra_artists kwarg so we
1783 # need this conditional....
1784 try:
-> 1785 bbox = ax.get_tightbbox(
1786 renderer, bbox_extra_artists=bbox_extra_artists)
1787 except TypeError:
1788 bbox = ax.get_tightbbox(renderer)
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib/axes/_base.py:4388, in _AxesBase.get_tightbbox(self, renderer, call_axes_locator, bbox_extra_artists, for_layout_only)
4386 if ba:
4387 bb.append(ba)
-> 4388 self._update_title_position(renderer)
4389 axbbox = self.get_window_extent(renderer)
4390 bb.append(axbbox)
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib/axes/_base.py:2963, in _AxesBase._update_title_position(self, renderer)
2960 bb = None
2961 if (ax.xaxis.get_ticks_position() in ['top', 'unknown']
2962 or ax.xaxis.get_label_position() == 'top'):
-> 2963 bb = ax.xaxis.get_tightbbox(renderer)
2964 if bb is None:
2965 if 'outline' in ax.spines:
2966 # Special case for colorbars:
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib/axis.py:1325, in Axis.get_tightbbox(self, renderer, for_layout_only)
1322 renderer = self.figure._get_renderer()
1323 ticks_to_draw = self._update_ticks()
-> 1325 self._update_label_position(renderer)
1327 # go back to just this axis's tick labels
1328 tlb1, tlb2 = self._get_ticklabel_bboxes(ticks_to_draw, renderer)
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib/axis.py:2304, in XAxis._update_label_position(self, renderer)
2300 return
2302 # get bounding boxes for this axis and any siblings
2303 # that have been set by `fig.align_xlabels()`
-> 2304 bboxes, bboxes2 = self._get_tick_boxes_siblings(renderer=renderer)
2306 x, y = self.label.get_position()
2307 if self.label_position == 'bottom':
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib/axis.py:2099, in Axis._get_tick_boxes_siblings(self, renderer)
2097 for ax in grouper.get_siblings(self.axes):
2098 axis = getattr(ax, f"{axis_name}axis")
-> 2099 ticks_to_draw = axis._update_ticks()
2100 tlb, tlb2 = axis._get_ticklabel_bboxes(ticks_to_draw, renderer)
2101 bboxes.extend(tlb)
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib/axis.py:1262, in Axis._update_ticks(self)
1257 def _update_ticks(self):
1258 """
1259 Update ticks (position and labels) using the current data interval of
1260 the axes. Return the list of ticks that will be drawn.
1261 """
-> 1262 major_locs = self.get_majorticklocs()
1263 major_labels = self.major.formatter.format_ticks(major_locs)
1264 major_ticks = self.get_major_ticks(len(major_locs))
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib/axis.py:1484, in Axis.get_majorticklocs(self)
1482 def get_majorticklocs(self):
1483 """Return this Axis' major tick locations in data coordinates."""
-> 1484 return self.major.locator()
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib/ticker.py:2135, in MaxNLocator.__call__(self)
2134 def __call__(self):
-> 2135 vmin, vmax = self.axis.get_view_interval()
2136 return self.tick_values(vmin, vmax)
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib/axis.py:2206, in _make_getset_interval.<locals>.getter(self)
2204 def getter(self):
2205 # docstring inherited.
-> 2206 return getattr(getattr(self.axes, lim_name), attr_name)
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib/axes/_base.py:857, in _AxesBase.viewLim(self)
855 @property
856 def viewLim(self):
--> 857 self._unstale_viewLim()
858 return self._viewLim
File ~/Library/Python/3.9/lib/python/site-packages/matplotlib/axes/_base.py:848, in _AxesBase._unstale_viewLim(self)
841 def _unstale_viewLim(self):
842 # We should arrange to store this information once per share-group
843 # instead of on every axis.
844 need_scale = {
845 name: any(ax._stale_viewlims[name]
846 for ax in self._shared_axes[name].get_siblings(self))
847 for name in self._axis_names}
--> 848 if any(need_scale.values()):
849 for name in need_scale:
850 for ax in self._shared_axes[name].get_siblings(self):
KeyboardInterrupt:
Support Vector Classification#
Binary classifier that finds a hyperplane that separates the two classes of data
Can be extended to multiclass classification using a One-vs-Rest (OvR) approach
Also uses the kernel trick (like KRR) to modify the data to better fit nonlinear patterns (can find patterns that ridge classification cannot)
X = np.asarray(wine_data.drop(columns=['labels']))
y = np.asarray(wine_data['labels'])
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2)
svc = SVC(kernel='linear', C=1.0)
svc.fit(X_train, y_train)
y_pred = svc.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
Accuracy: 0.83
Can attempt to scale the data as well
scaler = StandardScaler()
scaler.fit(X)
Z = scaler.transform(X)
X_train, X_test, y_train, y_test = train_test_split(Z,y,test_size=0.2)
svc = SVC(kernel='linear', C=1.0)
svc.fit(X_train, y_train)
y_pred = svc.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
Accuracy: 0.94
Clustering#
What is Unsupervised Learning?#
Algorithms learn from unlabeled data (just the feature) with the goal of finding hidden patterns in the data
Examples of unsupervised learning tasks: clustering, dimensionality reduction, and anomaly detection
What is Clustering?#
Unsupervised learning technique where data is grouped into clusters based on similarity
Unsupervised learning version of classification, could be grouped in a workflow with classification
Algorithms: k-Means, heirarchical clustering analysis (HCA), DBSCAN
k-Means (KMeans)#
Used for partitioning data into clusters based on similarities in the data points
How does k-means work?#
Initialize the cluster centroids
Assign each data point to the closest centroid
Update the centroids to the center of each cluster
Repeat until convergence
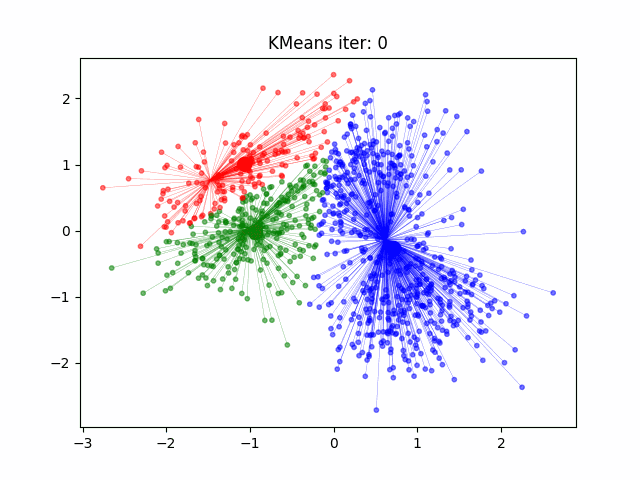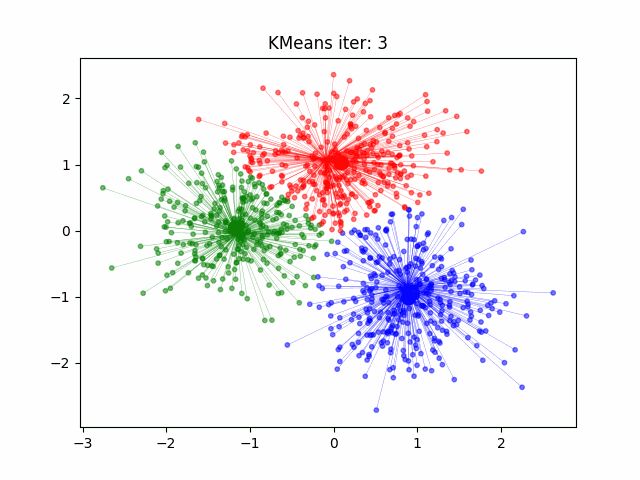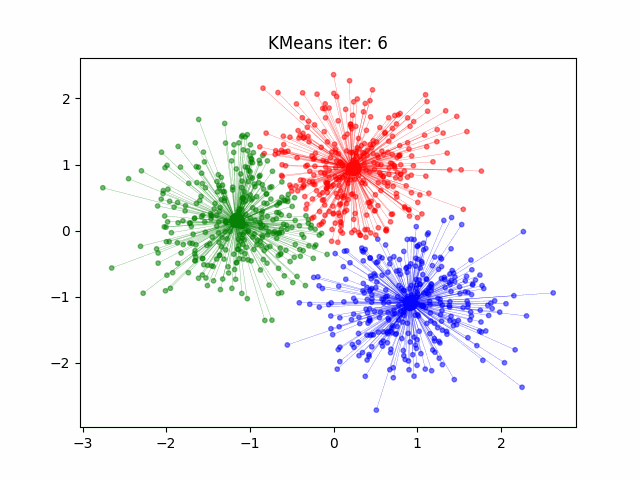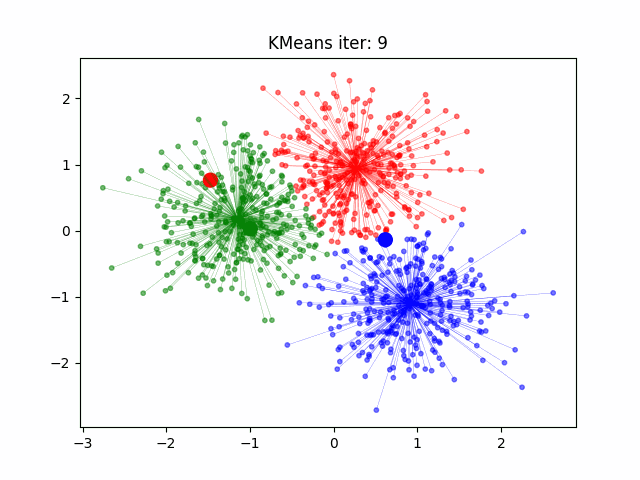
Measure of Success#
Within-Cluster Sum of Squares (WCSS) or Interia
The sum of the squared distances between each data point and the centroid of its cluster
Measure of the compactness of each cluster
Assuming We Know the Number of Clusters#
n_clusters = 3
kmeans = KMeans(n_clusters=n_clusters, n_init='auto')
# Fit the KMeans model
kmeans.fit(X)
# Predict the clusters
cluster_labels = kmeans.labels_
Plot the predicted clusters#
# Plot the clusters
plt.figure(figsize=(8, 6))
for i, color in zip(range(n_clusters), ['r', 'g', 'b']):
predicted_indices = np.where(cluster_labels == i)
plt.scatter(X[predicted_indices, 0], X[predicted_indices, 1], c=color, label=f'Predicted {y[i]} (Cluster {i})', marker='^', edgecolors='k', s=100)
plt.xlabel(wine.feature_names[0])
plt.ylabel(wine.feature_names[0])
plt.title('KMeans Clustering of Wine Dataset')
plt.legend()
<matplotlib.legend.Legend at 0x28ee2ca90>
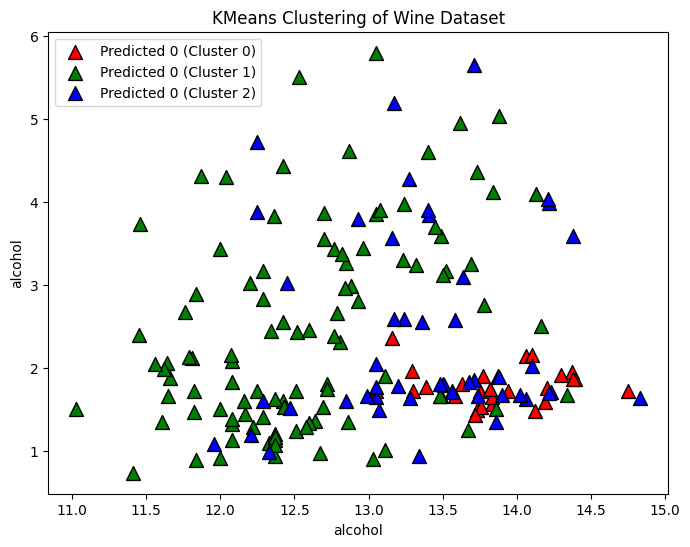
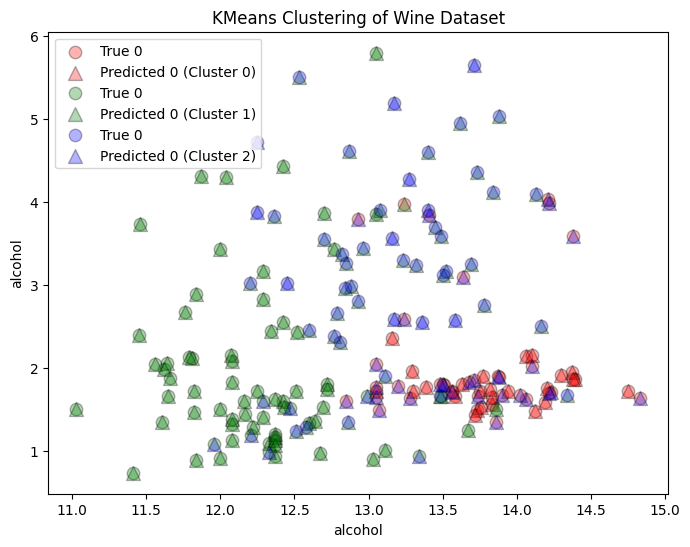
Compare to the True Clusters#
There is no error score or accuracy score because the algorithm is learning from unlabeled data
# Plot the clusters
plt.figure(figsize=(8, 6))
for i, color in zip(range(n_clusters), ['r', 'g', 'b']):
true_indices = np.where(y == i)
predicted_indices = np.where(cluster_labels == i)
plt.scatter(X[true_indices, 0], X[true_indices, 1], c=color, label=f'True {y[i]}', edgecolors='k', s=80, alpha=0.3)
plt.scatter(X[predicted_indices, 0], X[predicted_indices, 1], c=color, label=f'Predicted {y[i]} (Cluster {i})', marker='^', edgecolors='k', s=100, alpha=0.3)
plt.xlabel(wine.feature_names[0])
plt.ylabel(wine.feature_names[0])
plt.title('KMeans Clustering of Wine Dataset')
plt.legend()
plt.show()
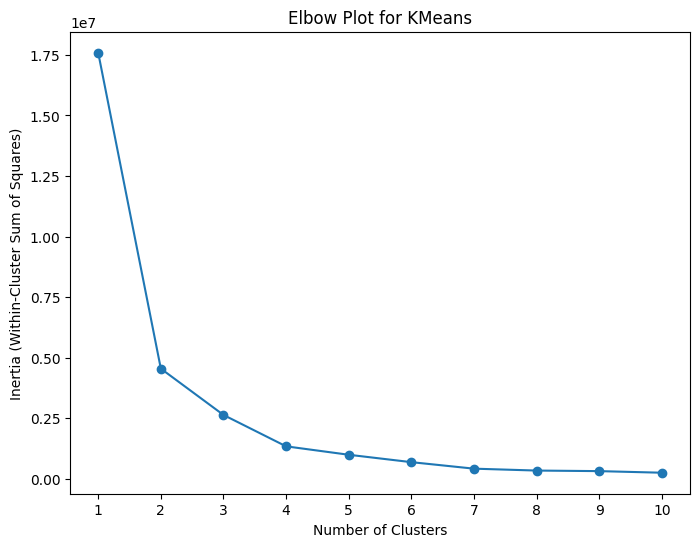
What if We Do Not Know the Number of Clusters?#
Method 1: Elbow Plot
Plot of WCSS vs. the number of clusters
Identify the “elbow”, the point at which the reduction in WCSS starts to slow down
# Calculate within-cluster sum of squares for different numbers of clusters
inertia_values = []
for n_clusters in range(1, 11):
kmeans = KMeans(n_clusters=n_clusters, n_init='auto')
kmeans.fit(X)
inertia_values.append(kmeans.inertia_)
# Plot the elbow plot
plt.figure(figsize=(8, 6))
plt.plot(range(1, 11), inertia_values, marker='o')
plt.xlabel('Number of Clusters')
plt.ylabel('Inertia (Within-Cluster Sum of Squares)')
plt.title('Elbow Plot for KMeans')
plt.xticks(np.arange(1, 11))
plt.show()
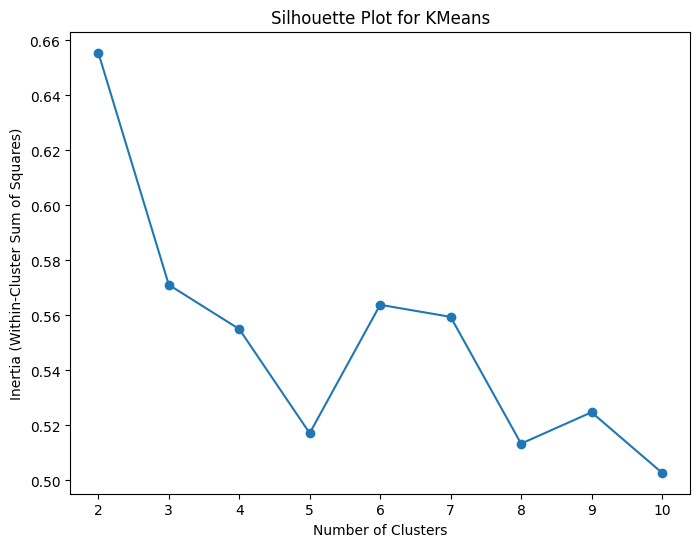
Method 2: Silhouette Scores
Measure of how well-separated and distinct the clusters are
Close to +1 means well clustered with a clear separation between clusters
Close to 0 means overlapping and crowded clusters
Close to -1 means data points may have been misclassified
# Calculate within-cluster sum of squares for different numbers of clusters
silhouette_values = []
for n_clusters in range(2, 11):
kmeans = KMeans(n_clusters=n_clusters, n_init='auto')
kmeans.fit(X)
silhouette_values.append(silhouette_score(X, kmeans.labels_))
# Plot the elbow plot
plt.figure(figsize=(8, 6))
plt.plot(range(2, 11), silhouette_values, marker='o')
plt.xlabel('Number of Clusters')
plt.ylabel('Inertia (Within-Cluster Sum of Squares)')
plt.title('Silhouette Plot for KMeans')
plt.show()
Need to set initialization and convergence criteria for Kmeans algorithms
Scikit-Learn does provide defaults
Random initialization: Initial centroids are randomly placed, and can suffer from poor convergence
KMeans++ selects centroids more intelligently with probability
Challenges of KMeans: sensitivity to initialization, handling outliers, determining the optimal number of clusters
Dimensionality Reduction#
Reducing the number of dimensions in the data set while preserving the essential information needed to train a model
High dimensional data can lead to overfitting, increased complexity, and poorcomputational efficiency
Two main ways to reduce dimensions: feature selection selects a subset of original features, while feature extraction creates new features
General machine learning workflow will involve peforming dimensionality reduction of the features of the data set (unsupervised learning) and the use of those reduced features and the data set labels to train a classification or regression model (supervised learning)
Principal Component Analysis (PCA)#
A dimensionality reduction technique used to transform high-dimensional data into lower-dimensional data while retaining as much variance as possible
Benefits: reduced noise and complexity, improved visualization and computational effiecency
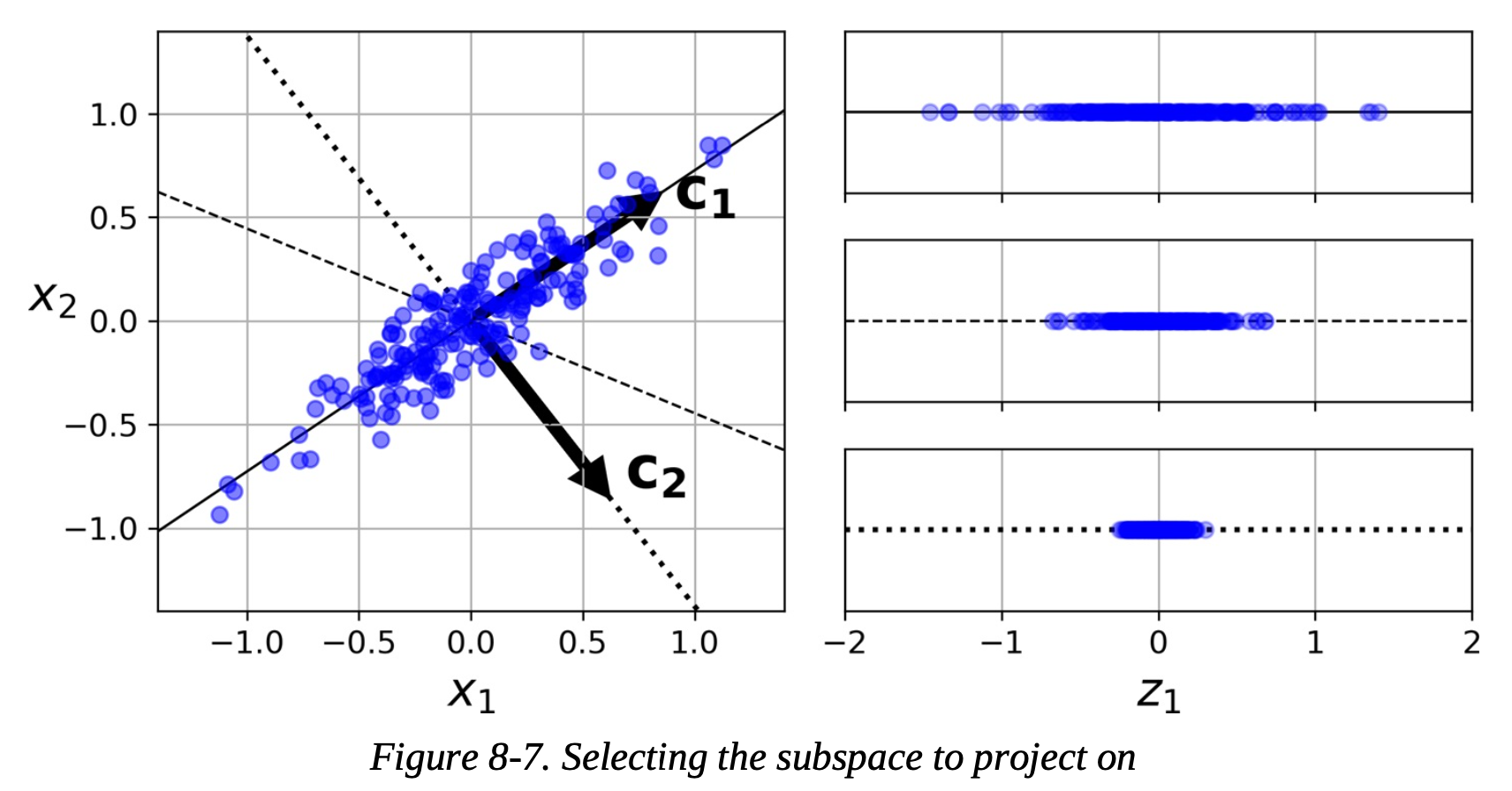
How does PCA Work?#
Standardize the data (data must be standardized for PCA)
Calculate the covariance matrix
Covariance matrix: each elements represents the covariance between two variables
Covariance is a measure of how two variables change together
Calculate the eigenvectors and eigenvalues of the covariance matrix
Select principal components based on eigenvalues
largest eigenvalue of the covariance matrix has the eigenvector (principal component) that captures the most variance
Transform the data to lower dimension
Create a transformation matrix where the principal components are the columns and multiply the transformation matrix by the original data. This is a projection.
Interpretability and Challenges#
The principal components can be interpreted as linear combinations of the original features but the lower dimensional data has no physical interpretation.
Limitations
Dimensionality reduction can lead to a potential loss of information
Complex relationships in the data may not be perserved
The data set has to be scaled before applying PCA
PCA works best when there are correlations between the features
To start with, let’s attempt to reduce the number of features in our wine data set from 6 to 13. Even with just this initial guess in the number of principal components, we should be an improvement in th accuracy score.
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(Z, y, test_size=0.2)
# Perform PCA for dimensionality reduction
pca = PCA(n_components=6) # Choose the number of principal components
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
# Initialize the Support Vector Classifier
svc = SVC(kernel='linear', C=1.0, random_state=42)
# Train the SVC on the PCA-transformed training data
svc.fit(X_train_pca, y_train)
# Predict the classes on the PCA-transformed test data
y_pred = svc.predict(X_test_pca)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
Accuracy: 0.97
Next we need to determine what the best number of components is in our model. We can think of this as hyperparameter tuning (like we covered last week). The first method we can try is to use a basic for loop and iterate over the possible number of principal components and test the accuracy at each new value. We can then train the model using the PCA results from the best number of components.
for i in range(1,13):
# Perform PCA for dimensionality reduction
pca = PCA(n_components=i) # Choose the number of principal components
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
# Initialize the Support Vector Classifier
svc = SVC(kernel='linear', C=1.0, random_state=42)
# Train the SVC on the PCA-transformed training data
svc.fit(X_train_pca, y_train)
# Predict the classes on the PCA-transformed test data
y_pred = svc.predict(X_test_pca)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Number of Components:", i, f"Accuracy: {accuracy:.2f}")
Number of Components: 1 Accuracy: 0.86
Number of Components: 2 Accuracy: 1.00
Number of Components: 3 Accuracy: 1.00
Number of Components: 4 Accuracy: 0.97
Number of Components: 5 Accuracy: 1.00
Number of Components: 6 Accuracy: 0.97
Number of Components: 7 Accuracy: 0.97
Number of Components: 8 Accuracy: 0.97
Number of Components: 9 Accuracy: 1.00
Number of Components: 10 Accuracy: 1.00
Number of Components: 11 Accuracy: 1.00
Number of Components: 12 Accuracy: 1.00
pca = PCA(n_components=7) # Choose the number of principal components
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
# Initialize the Support Vector Classifier
svc = SVC(kernel='linear', C=1.0, random_state=42)
# Train the SVC on the PCA-transformed training data
svc.fit(X_train_pca, y_train)
# Predict the classes on the PCA-transformed test data
y_pred = svc.predict(X_test_pca)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
Accuracy: 0.97
Instead of just doing the for loop method for finding the best number of components, you can also use GridSearchCV and RandomizedSearchCV as well. Additionally, by making use of the Pipeline feature from Scikit-Learn, you can tune both your PCA and your machine learning model simultaneously. Here we use Pipeline to link the standard scaler, PCA, and the support vector classifier together and then use RandomizedSearchCV to tune the number of PCA components and two hyperparameters from the support vector classifier.
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(Z, y, test_size=0.2)
# Create a pipeline with PCA and SVC
pipeline = Pipeline([
('scaler', StandardScaler()),
('pca', PCA()),
('svc', SVC())
])
# Define parameter distributions for RandomizedSearchCV
param_dist = {
'pca__n_components': [2, 5, 8], # Number of principal components
'svc__C': uniform(0.1, 10), # Regularization parameter C
'svc__kernel': ['linear', 'rbf'], # Kernel type
}
# Initialize RandomizedSearchCV
random_search = RandomizedSearchCV(pipeline, param_distributions=param_dist, n_iter=100)
# Fit the RandomizedSearchCV on training data
random_search.fit(X_train, y_train)
# Print the best hyperparameters
print("Best Hyperparameters:", random_search.best_params_)
# Predict the classes on the test data
y_pred = random_search.predict(X_test)
# Calculate accuracy
accuracy = np.mean(y_pred == y_test)
print(f"Accuracy: {accuracy:.2f}")
Best Hyperparameters: {'pca__n_components': 8, 'svc__C': 0.6660029547793321, 'svc__kernel': 'rbf'}
Accuracy: 0.97
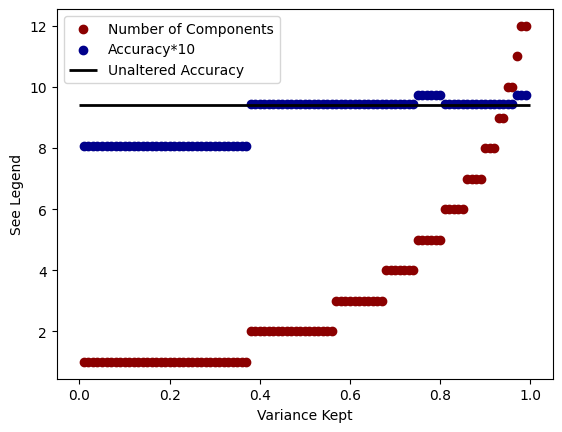
Finally, instead of passing the PCA algorithm the number of components you want, you can instead pass it a number between 0.0 and 1.0 (exclusive). This number correpsonds to the amount of variance in the data you wish to preserve. The more variance kept the greater the differentiation among the data will be, but likely the more components that will be needed as well.
pca = PCA(n_components=0.95) # Choose the variance
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
print("Number of PCA Components:", pca.n_components_)
# Initialize the Support Vector Classifier
svc = SVC(kernel='linear', C=1.0, random_state=42)
# Train the SVC on the PCA-transformed training data
svc.fit(X_train_pca, y_train)
# Predict the classes on the PCA-transformed test data
y_pred = svc.predict(X_test_pca)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
Number of PCA Components: 10
Accuracy: 0.94
for i in range(1,100):
i /= 100
pca = PCA(n_components=i) # Choose the number of principal components
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
plt.scatter(i,pca.n_components_, color='darkred', label='Number of Components'if i == 0.99 else "_nolegend_")
# Initialize the Support Vector Classifier
svc = SVC(kernel='linear', C=1.0, random_state=42)
# Train the SVC on the PCA-transformed training data
svc.fit(X_train_pca, y_train)
# Predict the classes on the PCA-transformed test data
y_pred = svc.predict(X_test_pca)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
plt.scatter(i,accuracy*10, color='darkblue', label='Accuracy*10'if i == 0.99 else "_nolegend_")
plt.hlines(9.4, 0.0, 1.0, linewidth=2, color='k', label="Unaltered Accuracy")
plt.legend()
plt.xlabel("Variance Kept")
plt.ylabel("See Legend")
Text(0, 0.5, 'See Legend')
PCA may not seem very useful for the data sets we encounter in this class, but many real world data sets can have hundreds or thousands of different features, and not all of them will be relevant.